Imagine ChatGPT or any other existing LLM as it has an eye, that eye can only see and understand the context of your conversation/text through a Window, that Window has a limited length (which is 4000 words for ChatGPT-3.5)
If you started a new conversation with ChatGPT, the Window is at the start of your conversation, when you continue to chit-chat with it, and as the conversation gets longer the Window moves down…
at a certain conversation length, ChatGPT doesn’t recognize the context about the conversation start,
and So on…
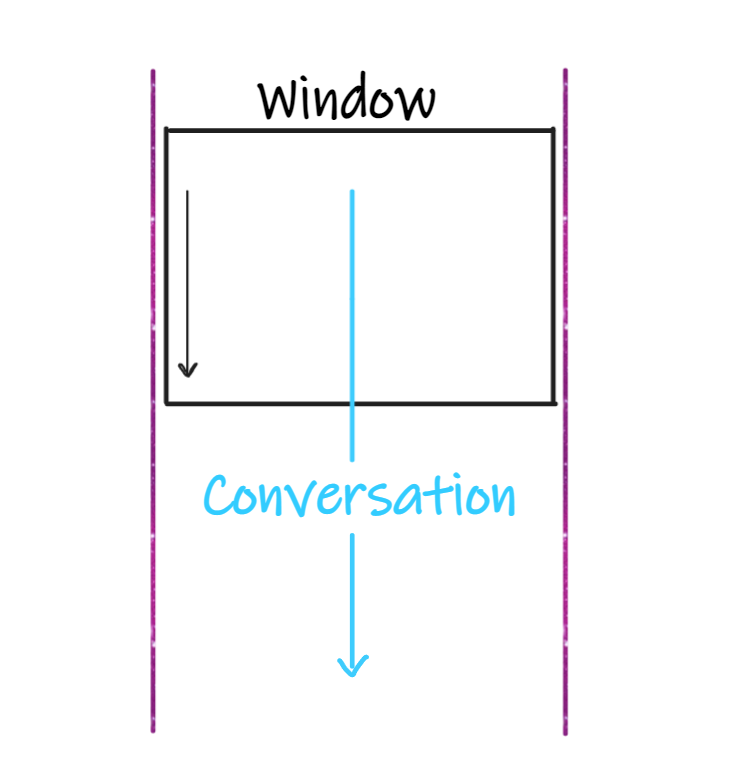
That Window length includes your new message, and the ChatGPT upcoming answer:
So, Whatever you prompt ChatGPT with most advanced prompts, it will not remember ![]() .
.